Threads und hardwareseitiges Multithreading
Sobald wir einen Computer einschalten, werden "gleichzeitig" viele Aufgaben (Tasks) abgearbeitet. Selbst wenn vom
Benutzer keine Eingabe erfolgt, beschäftigt sicher der Rechner mit den Dingen, die ihm das Betriebssystem
aufgibt, wie zum Beispiel Bild aufbauen, auf Eingabe warten, Internet herstellen etc. Mit einem Windows-Rechner kann man
das sehr einfach überprüfen, wenn man die Tasten Strg + Alt + Entf
gleichzeitig drückt. Unter "Task-Manager" sind die im Moment laufenden und wartenden Tasks aufgezählt. Zum
Teil sind es Dienste von Windows. Aber auch einige Programme laufen bereits und warten auf Eingaben des Benutzers.
Unter Windows 10 können problemlos mehr als 100 Task laufen. Jeder Task wird in einem Thread ausgeführt. Von
außen sieht es so aus, als ob alle Threads gleichzeitig laufen. In Wirklichkeit bekommt jeder Thread vom
Betriebssystem einen Zeitbereich, in dem er den Prozessor für sich alleine verwenden darf (softwareseitiges
Multithreading).
In Zeiten des legendären C64, dessen Prozessor mit einer Taktfrequenz von etwa einem MHz lief,
durften sich natürlich nicht allzu viele Threads die Prozessor-Zeit teilen. Aber immerhin, wenn in einer Sekunde
eine Million Takte zur Verfügung stehen, dürfte es kein Problem sein, 10 Threads unterzubringen, - sofern keiner
von ihnen den Prozessor über die Gebühr fordert. Wer allerdings eine aufwendige Rechnung durchführen ließ,
musste häufig erleben, dass der Rechner wie "einfroren" wirkte und auf Eingaben nicht mehr reagierte.
In den Jahren danach schraubte man die Taktfrequenz der Prozessoren bis auf 4-5 GHz hoch.
Aber gleichzeigig wuchs die Anzahl der Threads und gegebenenfalls auch die Komplexität der vom Benutzer
verlangten Rechenaufgaben. Man könnte auf den Gedanken kommen, dass man die Taktfrequenz einfach nochmals vertausendfacht,
denn dann wären tausend Mal mehr Zeitabschnitte zu vergeben. Leider zeigte sich, dass man mit 4 GHz an einer Grenze
ankommt, die mit vernüftigem Aufwand kaum zu überwinden ist. So entstand die Idee, auf einem Prozessor mehrere
weitgehend autarke Prozessorkerne (Cores) unterzubringen. Heutige Prozessoren haben meist vier oder mehr Cores.
Wenn der Benutzer keine höchst anspruchsvolle Rechnung durchführen lässt, haben die Cores wenig zu tun. Mehr
zu tun bekommt ein Prozessorkern, wenn man ihn so im Rechner einbindet, dass das Betriebssystem zwei Kerne "sieht".
Diese Technik nennt sich "Hyper-Threading". Steht diese Technik zur Verfügung, dann verdoppelt sich scheinbar die Anzahl
der Cores für das Betriebssystem.
Nehmen wir an, ein Rechner habe 4+4 Prozessor-Kerne. Selbst wenn diese nur mit einer Frequenz von
1 GHz takten, ist seine "Schwuppdizität" (= gefühlte Geschwindigkeit) größer, als die eines Rechners mit
einem Prozessorkern aber 4 GHz Takt. Das Betriebssystem kann im ersten Fall manche Threads auf die verschiedenen
Cores verteilen, wo sie dann die Chance haben, gleichzeitig abgearbeitet werden können. Warum nur die Chance?
Wenn ein Thread auf einem Core ein Zwischenergebnis eines auf einem anderen Core laufenden Threads benötigt,
dann gibt es Probleme. Sind die Threads unabhängig, wie zum Beispiel viele Dienste des Betriebssystems, dann
können sie problemlos auf die Cores verteilt werden. Dies wird vom Betriebssystem selbst gemanagt.
Wir beschäftigen uns hauptsächlich mit der Erzeugung von Bildern. Ein Bild aber kann man in mehrere Abschnitte
unterteilen. In manchen Fällen sind die Berechnungen der Teilbilder völlig unabhängig von einander. Und genau
damit wollen wir uns in diesem Kapitel beschäftigen. Bei einem Rechner mit 8+8 Cores kann man die Berechnung
eines Bildes auf ein zwölftel der Zeit mit nur einem Core drücken.
Bevor wir mit den Bildern beginnen, zeigen wir, wie die Methode bei einer sehr umfangreichen Rechnung funktioniert.

Der Schleifenparameter j steht für die Nummer des Core (beginnend bei Null). Bei 8+8 Cores sind 16 parallel laufende
Schleifen zu durchlaufen. Dass die Rechnung äußerst umfangreich ist, erkennt man an dem maximalen Schleifenparameter
i von 100 Millionen und natürlich an den Funktionen sin, cos und Wurzel. Lässt man diese Rechnung auf einem
recht schnellen Rechner (4 GHz) ohne Aufteilung der Rechnung an einzelne Cores durchlaufen, dann benötigt man
dafür etwas mehr als 10 Minuten. Ganz anders sieht es aus, wenn man den Sketch so schreibt, dass hardwareseitiges
Multithreading durchgeführt wird. (Die durchzuführende Rechnung lässt sich auch mit z.B. 2+2 Cores verteilen:
Jeder Thread bekommt dann vier j Schleifen zugeordnet). Hier der Ergebnis-Ausdruck für 16 Threads:
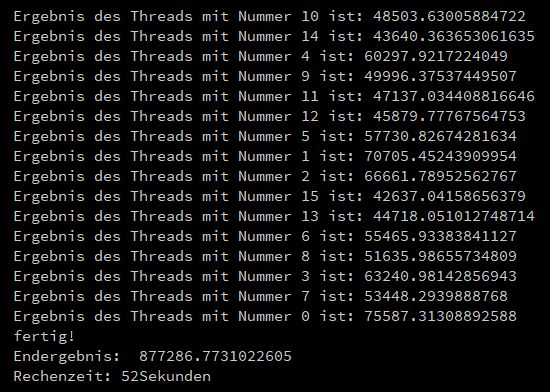
Das Ergebnis bekommt man hier nach etwa einem zwölftel der Zeit in Vergleich zum Single-Thread Sketch.
Weshalb nicht 16 mal so schnell mit 16 Threads? Zur Hauptsache liegt das daran, dass die Cores nicht nur
die Rechenaufgaben abarbeiten. Wie oben erwähnt, sind nebenbei noch viele andere Threads vorhanden, die immer
wieder ihren Anteil an Zeit auf den Cores beanspruchen. Außerdem ist ja nicht gesagt, dass alle Rechnungen
gleich lang dauern. Vielleicht braucht ein Thread doppelt so lang, wie die anderen.
Zugegebenermaßen ist die Rechnung äußerst künstlich konstruiert, indem darauf geachtet wurde, dass die Aufgaben
in etwa gleich aufwendig sind. Und hier sind wir bereits beim Hauptproblem des hardwareseitigen Multithreadings:
Das Erstellen eines Algorithmus, der die Aufgaben möglichst gleichmäßig auf die Cores verteilt, ohne dass dabei
von verschiedenen Threads gleichzeitig auf einen Speicher geschrieben wird. Um keine falsche Hoffnungen aufkommen
zu lassen, sei festgestellt, dass es Aufgaben gibt, die sich beim besten Willen nicht verteilen lassen. Und das
Betriebssystem selbst ist, wie man oben gesehen hat, in solchen Fällen auch nicht hilfreich. Zum Glück interessieren
uns ja hauptsächlich Bilder. Und ihre Berechnung kann man, wie wir später sehen werden, in manchen Fällen tatsächlich
sehr einfach verteilen: Jeder Core bekommt einen gleich großen Teil des Bildes zugeordnet. Und wenn die Rechnungen
für die Bildabschnitte nicht von anderen Bildabschnitten abhängen, kann man die Beschleunigungstechnik problemlos
anwenden.
Zurück zum Sketch mit der verteilten Rechnung. Wir verwenden dazu eine Klasse Threads, die aber auch ganz
anders heißen könnte. Hier der zugehörige kommentierte Quellcode:
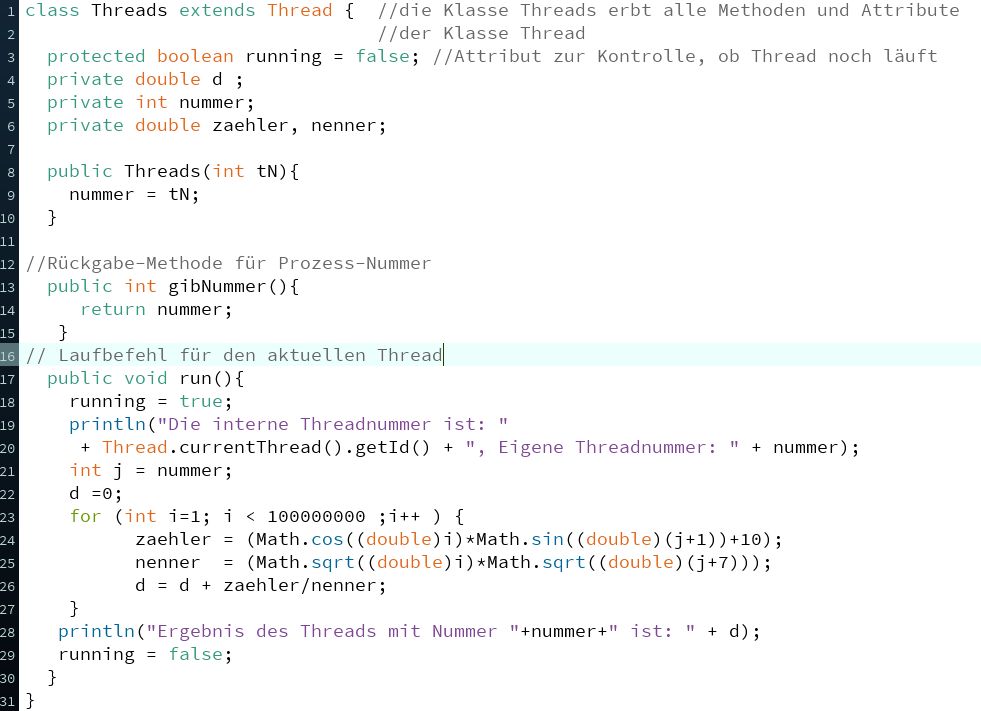
(Wir lassen hier die interene und die eigene Threadnummer mit ausgeben, um zu zeigen, dass diese meist nicht
gleich sind.)
Die Hauptklasse ruft den Laufbefehl "run" genau so oft auf, wie es Cores gibt. Hier der Quellcode:
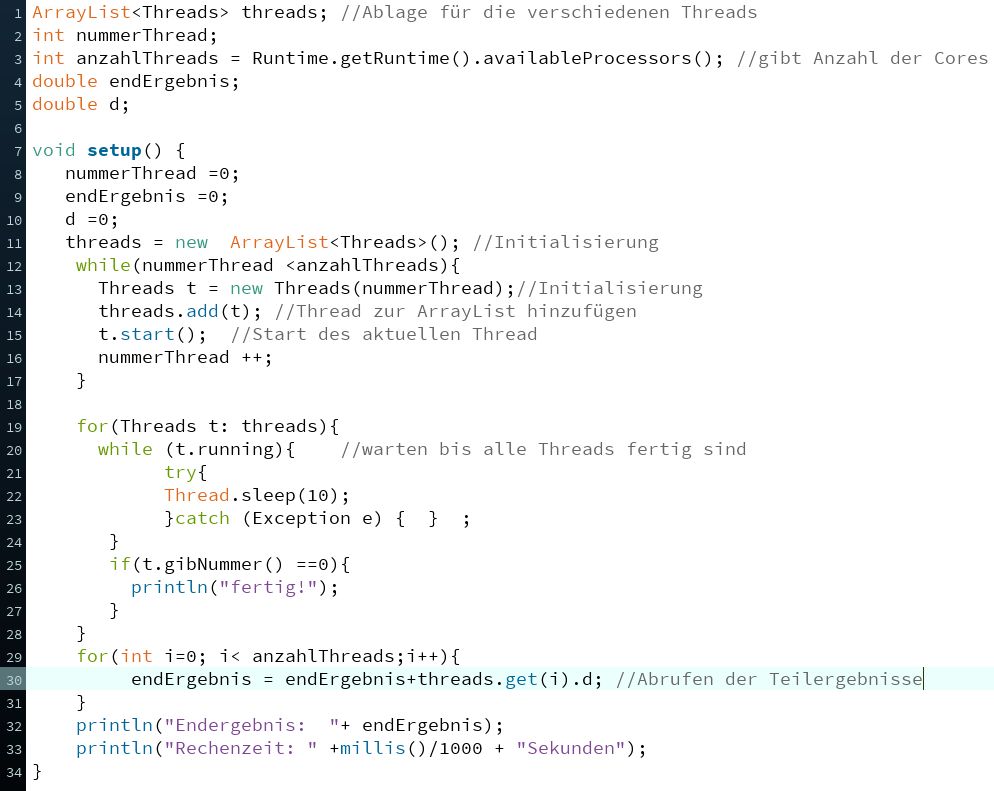
Man kann in obigem Code sehr schön erkennen, dass gewartet wird, bis alle Threads fertig gerechnet haben. Ebenso
ist zu erkennen, dass jeder Thread seinen eigenen Speicherbereich besitzt.
Nun zu den Bildern. Im Lehrbuch aber auch hier wurde die Technik bereits vielfach angewendet. Die Idee ist,
recht einfach. Das folgende Bild zeigt die bekannte Mandelbrotmenge (schwarz). Die waagerechten Linien zeigen an,
wie die Berechnung es Bildes in Teilbilder für die einzelnen Cores zerlegt wurde:

Die Klasse Threads unterscheidet sich kaum vom obigen Beispiel:

Der wesentliche Punkt ist, dass jeder Thread einen eigenen Bildbereich pg der Klasse PGraphics besitzt.
Und erst wenn alle Bildbereiche fertiggerechnet wurden, werden sie in der Hauptklasse zusammengesetzt.

Hier können die behandelten Sketche runtergeladen werden:
SingleThreadRechnung
MultiThreadRechnung
MultiThreadMandelbrot
Menu